



Photo by Taylor Vick on Unsplash
Dev's Journal 4
Testnet Deployments, UMA Finance Success Tokens, and State Machines


Welcome back to the Dev's Journal. I felt like I didn't have many interesting things to say as I was working this week, and then I sat down to compile my notes. There's been a lot going on! This week I cover the Testnet deployment and infrastructure we're building out to run a new OlympusDAO system through its paces, research I did on UMA Finance's Success Tokens, and thoughts about modeling systems as State Machines. Let's dive in.
Building Testnet Deployment Infrastructure
We recently sent a set of smart contracts to audit at OlympusDAO. One of the first follow-up questions we got from the auditors was: "Do you have a testnet deployment up that we can look at as well?". We did not, but it's something we were actively working towards (between all the iterations to get ready for the audit, some stuff gets put in the do later pile). This is probably a common request, but I thought the reasoning they gave provided some insight into how they go about their process:
"The advantage of a testnet deployment is that we can see all the state variables assigned with values close or identical to what you would also use in production. This allows auditors to reason on plausible scenarios, rather than theoretical setups, when assessing impact. It also allows us to better simulate complex multi-protocol scenarios if need be."
We were already planning to do a full testnet deployment and integration test of the system. Additionally, we are trying to setup a more extensive internal testing exercise with other DAO members to observe the behavior in a quasi-live environment. While we have to be able to deploy everything and connect it anyways to deploy to production, there are some quirks with testnets that require a bit more effort and infrastructure. With the auditors request coming in as well and having the code frozen, this rose to the top of my list this week.
Choosing a Testnet
A standard deployment usually includes:
- A script or scripts to deploy the system contracts
- A way to verify the contracts on popular block explorers (i.e. Etherscan)
- Deployment and configuration of off-chain infrastructure to support the system, such as:
- Bot services (including servers to host them and software to manage/monitor them)
- Front-end applications
- Event indexers (e.g. subgraphs)
Testnet deployments also have to contend with:
- Deploying external dependencies
- Being unable to rely on efficient market dynamics for certain features (examples of this are MEV/arbitrage bots)
One thing that you can take for granted with production deployments is that external contracts you're integrating with will be there and "just work" (assuming you integrate correctly). However, this often isn't the case with a testnet. Therefore, you end up needing to deploy the actual version or mocks of your external dependencies to get it to work. For simple systems, this isn't bad, but it can be a lot of work for something complex (like a lending protocol). Because of the additional complexity in setting up external dependencies, it often effects the decision of which testnet a team will use. For example, OpenSea has supported a testnet deployment of the Wyvern protocol with a full API that mirrors Mainnet on Rinkeby, so a lot of NFT developers would use Rinkeby to ensure the integration with their marketplace went well. Chainlink on the other hand supports both Kovan and Rinkeby testnets with some of their products. Other reasons to choose different testnets are availability of testnet Ether (recently an issue on Rinkeby) and block times (some can be faster or slower than Mainnet depending on consensus mechanism and settings) among other client specific differences. Another option that some developers prefer is using an alternate L1 as a testnet for Ethereum Mainnet, such as Polygon's PoS chain. One benefit of this is that a lot of external dependencies do exist on Polygon (Uniswap, Sushiswap, Aave, Opensea, etc.). It does cost some real money since you need MATIC to use the network, but the cost is typically pretty reasonable and may be worth it.
Additionally, many testnets are going to be sunset overtime as a result of the Merge. These include Rinkeby, Ropsten, and Kiln. Both Pyrmont (beacon chain testnet) and Kovan (execution layer testnet) were sunset recently. Post-merge, the main Ethereum testnets will be Görli and Sepolia. As a result, we've chosen to use Görli going forward and have redeployed all of the Olympus contracts (existing and now the new ones we're testing) there to prepare for various testing activities. One aspect of Görli that was appealing is that, even though it's a PoA chain, there is a PoW faucet so you can mine decent amounts of test Ether. When I started using it you could mine up to 35 ETH in 3 hours just using your CPU on the web page. Although, I think the team and I mined too much, they had to do a "halvening" on rewards the other day so now it's down to 17 ETH in 3 hours 😂. I'll send back what we don't use, but, as you'll see below, we may end up spending a lot of it.
Solving for external dependencies
The only non-Olympus dependency of the new system is the OHMv2/ETH Chainlink Price Feed. However, it turns out that Chainlink Price Feeds are not available on Görli to test against (the OHMv2/ETH one is not on ANY testnets). Therefore, we needed to come up with a solution for providing data to our system so that we could test it. It would be nice if the data that is the same or close to what it would be live. In Chainlink's GitHub repository, they provide a simple MockAggregator contract that can be used for testing. It is essentially a storage bucket that you can write data values to and then have your system read them. I had taken this contract and expanded it a bit to implement the function on the AggregatorV2V3Interface for our local testing.
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
import {AggregatorV2V3Interface} from "interfaces/AggregatorV2V3Interface.sol";
contract MockPriceFeed is AggregatorV2V3Interface {
int256 public s_answer;
uint8 public s_decimals;
function setLatestAnswer(int256 answer) public {
s_answer = answer;
}
function latestAnswer() public view override returns (int256) {
return s_answer;
}
function setDecimals(uint8 decimals_) public {
s_decimals = decimals_;
}
function decimals() external view override returns (uint8) {
return s_decimals;
}
/// Not implemented but required by interface
function latestTimestamp() external view override returns (uint256) {}
function latestRound() external view override returns (uint256) {}
function getAnswer(uint256 roundId)
external
view
override
returns (int256)
{}
function getTimestamp(uint256 roundId)
external
view
override
returns (uint256)
{}
function description() external view override returns (string memory) {}
function version() external view override returns (uint256) {}
// getRoundData and latestRoundData should both raise "No data present"
// if they do not have data to report, instead of returning unset values
// which could be misinterpreted as actual reported values.
function getRoundData(uint80 _roundId)
external
view
override
returns (
uint80 roundId,
int256 answer,
uint256 startedAt,
uint256 updatedAt,
uint80 answeredInRound
)
{}
function latestRoundData()
external
view
override
returns (
uint80 roundId,
int256 answer,
uint256 startedAt,
uint256 updatedAt,
uint80 answeredInRound
)
{}
}
After thinking about this for a bit, I realized I could deploy these MockPriceFeeds to the testnet and then create a bot service (see below) to read the data from Mainnet and update the mock each time there was a new data point.
Deploying and Initializing the System
We've been using forge as our build and test environment for the system and have leaned into the new scripting framework for deploying the contracts as well. I originally wrote a single deploy script (Deploy.sol) that would deploy our core framework components, all the system contracts, install and approve them on the Kernel, and configure initial access control. While this worked pretty well for an initial big bang, we ended up having to redeploy a few contracts and swap them out within the system (which was really easy given the service oriented architecture of the Default Framework). To do so, I ended up writing a few contract specific deploy scripts and think a modular approach to this (or having different variations as separate functions on the same Script contract) might be a better approach going forward.
I've talked about forge script a bit the past few weeks. As I've been using it, I've ran into some different challenges and thought it'd be helpful to share. I'm going to caveat this section: I really like foundry. Forge, cast, and anvil are all fast and work remarkable well for being very new tools. I have been pushing some of the newer features to the limit recently and am inevitably encountering some of their current limitations.
While forge script has fairly intuitive format for entering arguments, some script calls can get complicated, especially when there are function arguments to add. Therefore, it is useful to make calls that will be used more than once into shell scripts. This also allows you to refresh your environment variables from a .env file on each invocation. A typical deploy script for us looks like this, followed by the shell script that invokes it:
function deploy(address guardian_, address policy_) external {
vm.startBroadcast();
/// Deploy kernel first
kernel = new Kernel();
console2.log("Kernel deployed at:", address(kernel));
/// Deploy modules
...
PRICE = new OlympusPrice(
kernel,
ohmEthPriceFeed,
reserveEthPriceFeed,
uint48(8 hours),
uint48(120 days)
);
console2.log("Price module deployed at:", address(PRICE));
...
/// Deploy policies
...
heart = new Heart(kernel, operator, uint256(8 hours), rewardToken, 0);
console2.log("Heart deployed at:", address(heart));
...
/// Execute actions on Kernel
/// Install modules
kernel.executeAction(Actions.InstallModule, address(AUTHR));
kernel.executeAction(Actions.InstallModule, address(PRICE));
...
/// Approve policies
kernel.executeAction(Actions.ApprovePolicy, address(callback));
kernel.executeAction(Actions.ApprovePolicy, address(operator));
...
/// Set initial access control for policies on the AUTHR module
/// Set role permissions
/// Role 0 = Heart
authGiver.setRoleCapability(
uint8(0),
address(operator),
operator.operate.selector
);
/// Role 1 = Guardian
...
authGiver.setRoleCapability(
uint8(1),
address(operator),
operator.initialize.selector
);
...
/// Give roles to addresses
authGiver.setUserRole(address(heart), uint8(0));
authGiver.setUserRole(guardian_, uint8(1));
...
/// Terminate mock auth giver
kernel.executeAction(Actions.TerminatePolicy, address(authGiver));
vm.stopBroadcast();
}
source .env
forge script ./src/scripts/Deploy.sol:OlympusDeploy --sig "deploy(address,address)()" $GUARDIAN_ADDRESS $POLICY_ADDRESS --rpc_url $RPC_URL --private-key $PRIVATE_KEY --slow -vvv --broadcast --verify --etherscan-api-key $ETHERSCAN_KEY
When working with longish scripts (15-50 transactions), like the one above, I ran into some issues issues with the script sending transaction too quickly and the RPC rejecting them: EOA nonce unexpectedly changed. The problem is that the script runs faster than the RPCs can keep up with sometimes and so has to be throttled. Anything with multiple transactions hitting a live public network should use the --slow flag. I started out using an Alchemy RPC node, but it started rate limiting the scripts so I switched over to an Infura one for this use case. The good news is that if this does happen, you can rerun the script with the --resume flag and it will pick up where it left off (although I did have some repeat issues with Alchemy not resuming).
After deploying the new system, there are a few contracts that have to be initialized with a separate transaction call. This is because Policy contracts in the Default Framework cannot access their dependencies in the constructor function since the contract has not been approved by the Kernel yet. Therefore, I wrote another script to initialize the various contracts in the system:
function initialize(
uint256[] memory priceObservations,
uint48 lastObservationTime
) external {
// Set addresses from deployment
priceConfig = ...
operator = ...
heart = ...
/// Start broadcasting
vm.startBroadcast();
/// Initialize the Price oracle
priceConfig.initialize(priceObservations, lastObservationTime);
/// Initialize the Operator policy
operator.initialize();
/// Active the Heart policy by toggling the beat on
heart.toggleBeat();
/// Stop broadcasting
vm.stopBroadcast();
}
As you can see, the initialize function accepts a dynamic array of uint256 values to pass into the Price oracle so it can be provided with some historical data initially. This turned out to be quite an issue and took me down a couple dead ends.
First, the forge script documentation is sparse right now and there wasn't much information on how an array should be passed. I referenced the cast send docs since the transaction format is similar, but I didn't find anything there either. I was able to determine that cast sig would return the correct selector, so I needed to figure out how to structure the arguments. Next, I found the cast conversion command reference page and started making progress. I tried various strings of arrays with the values in them (both hex and decimal formats), but didn't have much luck. Then I discovered that forge script would accept a complete set of calldata like cast send instead of providing the selector and arguments in the command line.
It might be a good time to pause here and say that the array I was trying to format initially had 360 values in it before I reduced the configuration down to 90. That's probably well outside the typical use case, and I was pretty sure they hadn't tested these functions with that kind of input.
Once I decided to manually build the call data for my transaction, I referenced the Solidity documentation, which is actually pretty good in this area, to brush up on the dynamic array call data format for calling functions. The short version is that arguments get one slot per position immediately after the function selector. For an array, a pointer to another slot is inserted instead of the value so you can use more that one slot to specify the data. The first pointer goes after the last argument slot (in my case, slot 2 (since they are zero indexed) = 2 * 32 bytes = 64 bytes = 0x40). Then, in the slot referenced by the pointer, you specify the number of elements in the array. I had 90 elements (which is 0x5a in hexadecimal). Then I needed to insert my values in the 90 slots after that. To do so, I needed to convert all the array values to hexadecimal format, padded to the left with zeros in little endian format to match the uint256 specification. I wrote a quick shell script that leveraged the cast --to-uint256 conversion command to print them all to the terminal (I tried piping them to a file, but I gave up and just resorted to copy + paste). It was easier to use this tool than another since I had already input the values in an environment variable as an array in my earlier attempts.
source .env
# Loop through price array
for i in "${PRICES[@]}"
do
cast --to-uint256 $i
done
With the list of values, I pasted everything into an Excel sheet, removed the leading 0x from the values, and concatenated the values together into a single string of call data. After that it was matter of re-writing my script to use the call data and it should work.
# Load environment variables
source .env
# Deploy using script
forge script ./src/scripts/Deploy.sol:OlympusDeploy --sig $INITIALIZE_CALLDATA --rpc-url $RPC_URL --private-key $PRIVATE_KEY --slow --broadcast -vvvv
Unfortunately, it wasn't meant to be. While the script ran fine locally when simulated, I got a non-descriptive error when I tried to send the transactions to the network (picture is with 360 inputs which used a lot of gas, I lowered to 1/4 of that and had the same issue).
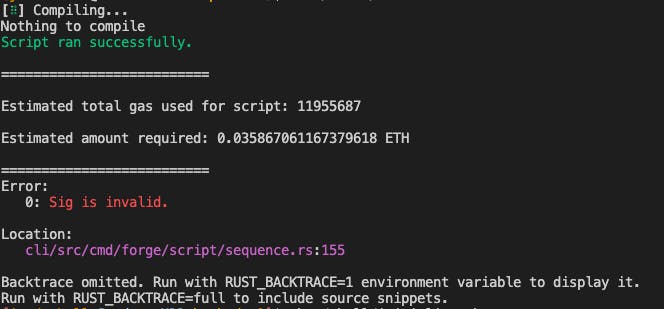
At this point, I didn't have any more ideas to troubleshoot it, so I did what any self respecting developer would do. I went to the Etherscan page with the verified contract, connected the permissioned dev wallet, pasted in all 90 values in a normally formatted array into the web form input, hit send, and it worked the first try. So much for that afternoon. Moral of the story is that certain use cases are overly complicated with forge script and cast. In a number of cases, ethers will be easier or even simpler solutions like the Etherscan front-end.
Setting up off-chain systems to support
In addition to deploying and configuring the smart contracts, we needed to get some off-chain systems ready to support our testing efforts. These included some bots to automate certain system actions and a front-end application that has been developed in parallel.
MockPriceFeed Bot
As I mentioned earlier, the solution I came up with to get around not having Chainlink Price Feeds on Görli was to use our MockPriceFeed contracts and have a bot update them with the data from Mainnet. That way, we have the same data as in the production environment at the same time it is published. For this component, I went with a tried and true solution I have used in other projects: a lightweight NodeJS script using ethers.js. In order to make it update on demand, the script needs to run perpetually (at least as long as it can) and have an event listener waiting for the Chainlink Price Feed aggregator on Mainnet to emit an AnswerUpdated event. Then, it needs to get the new value in the event callback function and write it to the mock contract on Görli. In order for this type of event listening to work, you have to use a Websocket RPC URL (wss:// instead of https://) since you need to maintain a persistent connection to the RPC (which is supported by Websockets and not HTTP). It's actually a fairly simple system:
const main = async () => {
console.log('Olympus Testnet Price Feed Bot starting...\n');
// Create provider and signer instances
const mainnetProvider = new ethers.providers.WebSocketProvider(process.env.MAINNET_WSS_URL);
const testnetProvider = new ethers.providers.JsonRpcProvider(process.env.TESTNET_URL);
const manager = new Wallet(process.env.PRIVATE_KEY, testnetProvider);
// Create contract instances
...
// Define event listener callbacks
const maxTries = 3;
const ohmEthMockCallback = async () => {
console.log('OHM-ETH Price updated. Updating on testnet...\n');
let updateTxn;
let updated = false;
let tries = 0;
// Define transaction overrides to ensure it clears
const feeData = await provider.getFeeData();
const overrides = { gasPrice: feeData['gasPrice'].mul(process.env.FEE_MULTIPLIER).div(100) };
while(!updated && tries < maxTries) {
tries++;
console.log(`Attempt #: ${tries}`);
try {
let latestAnswer = await ohmEthProxy.latestAnswer();
if (latestAnswer == ethers.constants.Zero) throw "Latest answer is zero";
updateTxn = await ohmEthMockManager.setLatestAnswer(latestAnswer, overrides);
await updateTxn.wait();
updated = true;
} catch (err) {
console.log(err);
}
}
if (updated) {
console.log("OHM/ETH price updated on testnet successfully.\n");
} else {
console.log("OHM/ETH price update on testnet failed.\n");
}
}
const reserveEthMockCallback = async () => {
...
}
// Set the mock prices when the bot starts up
console.log('Initializing mock price feeds to the latest prices...\n');
await ohmEthMockCallback();
await reserveEthMockCallback();
// Define event listeners
console.log('Creating event listeners for mainnet contracts.');
ohmEthAgg.on('AnswerUpdated', ohmEthMockCallback);
reserveEthAgg.on('AnswerUpdated', reserveEthMockCallback);
console.log('Listening for updates...');
};
Event listeners can be created in ethers.js by calling contract.on(), the first argument is a string of the Event name, and the second argument is the callback function.
The infrastructure for the bot is a free tier public cloud VM that uses the PM2 Process Manager to handle restarts if the service goes down. I've used this on other projects and it's robust enough for this use case.
Heartbeat Keeper Bot
In order for the system for function properly, it has a heartbeat function that triggers various updates and runs market operations logic each epoch (a term currently used by Olympus to refer to the rebasing frequency of sOHM). In order to ensure this logic runs, we've built a reward into the heartbeat contract for the address that successful calls it when able. We expect external users or services to provide this in production, but it needed to be replicated during testing.
While there are a number of keeper services on Mainnet (such as Keep3r network and Chainlink Keepers), I'm not aware of any that support Goerli at the moment. Additionally, we've built a simple keeper reward function into the contract that is open to anyone (not to a specific interface, this may change after audit/review).
In order to emulate a keeper, a wrote another simple bot to check when the heartbeat function can be called next, wait that amount of time, call it and then exit. I could have looped this and let it run continuously, but the logic is simpler if I just restart the service on a cron schedule equal to the frequency it will call the function.
const main = async () => {
console.log('Olympus Testnet Keeper Bot starting...\n');
// Create provider, signer, and contract instances
...
// Get the last beat time and the frequency to calculate the next beat time
const lastBeat = await heartKeeper.lastBeat();
const frequency = await heartKeeper.frequency();
const nextBeat = lastBeat.add(frequency).toNumber();
const currentTime = Math.round(new Date().getTime()/1000);
// Wait until the next beat, if necessary
if (currentTime < nextBeat) {
console.log(`Next beat is in ${nextBeat - currentTime} seconds. Waiting...\n`);
await sleep(nextBeat - currentTime);
}
// Define transaction overrides to ensure it clears
const feeData = await provider.getFeeData();
const overrides = { gasPrice: feeData['gasPrice'].mul(process.env.FEE_MULTIPLIER).div(100) };
// Try to call the heart.beat() function up to 3 times
let success = false;
let tries = 0;
const maxTries = 3;
let beatTxn;
console.log("Calling heart.beat()...");
while (!success && tries < maxTries) {
tries++;
console.log(`Attempt #: ${tries}`);
try {
beatTxn = await heartKeeper.beat(overrides);
await beatTxn.wait();
success = true;
} catch (err) {
console.log(err);
}
}
if (success) {
console.log("Heart beat successful.\n");
} else {
console.log("Heart beat failed.\n");
}
};
One pattern that is used here and was used in the other bot as well is to retry the transaction if it fails up to a certain number of times. On Mainnet, it would be smarter for a keeper to be judicious about when it calls and not do this repeatedly to keep down costs, but we're optimizing for reliability in this case. I am also setting the gas fee higher than suggested by the RPC to make the transactions faster.
The keeper bot is able to run on the same server as the price feed bot and is managed by the PM2 Process Manager as well. The only difference is that the keeper bot is re-run on a cron schedule every 8 hours since it is not a perpetual script.
Front-end Applications
Luckily, we have an awesome front-end team at Olympus. While we were focused on finishing up the smart contracts for audit, they took the mostly complete interfaces and built out initial versions of the front-end applications. This speeds up our timeline a bit and allows us to perform our testing with the interface most users will end up using to interact with the contracts. It also enables us to expand who is involved in the testing process and do more interesting exercises (like a competition to see who can accumulate the most OHM!).
Tying it all Together
After several days of work, I got all of my system components deployed, configured, and working together. It's a great feeling when the system starts running on its own. Here was the capstone moment:
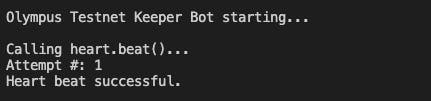
We still have some work to do to get the front-end connected and setup wallets for testers to use, but the core setup is done and gives me a good place to take a few days off from it.
Researching UMA/Outcome Finance Success Tokens
Success tokens are a mechanism for projects to raise money by selling a token that vests over time. The success token has a strike price where the payout will receive a bonus if the price is above the strike at maturity. The bonus increases as the price goes higher than the strike. If it is below the strike, the success token converts to a base amount of the underlying token.
Effectively, this is a two part investment. Base number of project tokens + call option (which is covered by the collateral posted by the project issuing them).
Success tokens configure two main parameters to determine split between base and call option:
collateralPerPairis the number of collateral backing each success tokenbasePercentageis the percent of the collateral that is paid out as the base.
Code Review
UMA has built a huge library of financial primitives that I don't think many people have looked at. I was pleasantly surprised by their depth. When I was researching this, it was for a fairly specific use case so I focused on a few key areas, but plan to go back later and look at others. Additionally, they have a really robust repository structure for all their different solutions built using yarn, hardhat, and TypeScript. Files reviewed:
LongShortPairs are tokens that use a combination of long and short tokens to tokenize a bounded price exposure to a given asset. LongShortPairFinancialProductLibrary contracts provide settlement payment logic. Success tokens are one of these settlement libraries. They have others like Range tokens, Binary options, covered calls, etc.
- Tokens are created through the
createfunction and then a strike price (and optionally base percentage) is set on the deploy financial product library. Two tokens are created and minted to the sender, "long" and "short". redeemis an eject function that returns the collateral for all the long and short tokens provided.settleallows exchanging a variable number of long and short tokens for an amount of collateral determined by the settlement on the financial product library.- Long Short Pairs (LSPs) let collateral be claimed by a variable amount by the long or short holders based on the settlement value provided by the library. In the case of Success Tokens, I believe the DAO receives the "short" tokens, while the purchaser receives the "long" tokens that are representing the call option portion of the payout.
Overall, Success tokens are an interesting way to create a differentiated incentive structure that benefits both DAOs and investors based on their sentiment.
Thinking about State Machines
I've been thinking about state machines recently as I've been working on a new paper presenting a formal definition of the math behind bond markets. I realized there are a lot of things that can be modeled as state machines.
Brief primer: A state machine is a mathematical abstraction used to represent a more complex system and can be useful to aid in reasoning about the system and designing algorithms that operate on the system. They are often drawn in a diagram and so also provide a visual representation of a system.
- A state machine takes a set of inputs and transitions to a different state based on the inputs. A finite state machine can be in exactly one of a finite number of states at any given time.
- A state is a set of values or properties of a system in between transitions.
- A transition is a set of actions that are executed to update values of the system when a trigger is received along with a set of inputs.
- Two types of finite state machines:
- Deterministic - only one possible action for any allowed input
- Non-deterministic - given a the current state, an input can lead to more than one new state
Things like smart contracts are simple to reason about in this way since the changes in to the state are atomic in the form of transactions. Messier concepts are things like a house. There aren't necessarily clear cut transitions between states, but you can abstract some of that mess and reason about it.
For example, consider clothing: assume all clothing starts clean in the closet after a laundry day. A person selects an outfit and puts it on. The state has changed. There is now less clothing in the closet and the person has more clothing. When the person takes off the clothing and puts it in the laundry basket. The state changes again. One interesting idea is that there is an "ideal" state for the house to be in (everything cleaned, put away, supplies stocked, etc.). This ideal state is the one in which the state of the house is able to best serve the needs of its inhabitants. Inhabitants are incentivized to push the house towards this state because it will benefit them in different ways. However, there are times when the system gets in a state of disarray due to the inhabitants not being able to perform their tasks or external events affecting the state (e.g. shortages, working too much, etc.).
In smart contracts, individual components or systems may not have an "ideal" state. For example, a Uniswap LP pool doesn't have a target price or amount of liquidity that it is trying to achieve. However, the broader economic network has an idealized state in that it trends towards equilibrium. By that, I mean that if there are multiple liquidity pools for the same token pair. Actors in the ecosystem will push them towards the same price, gaining profits from arbitraging the differences. Extreme market conditions make this equilibrium harder to maintain as more state changes happen and it is riskier for actors to push the state toward equilibrium.
Overall, many systems can be thought of as a state machine. If you're building a system that interacts with people (whether standalone or as part of a broader network), it can be helpful to consider what kind incentives they will have to engage with the system. If these incentives lead to undesirable states, then it is likely you will end up there.
It is hard to reason about large, complex state machines in your head, even if you're an elite shape rotator. The main way I've done so up to this point is by drawing them out with pen and paper and then breaking out specific transition components to reason about in more detail (e.g. specify how each variable changes). I was recently introduced to stately.ai, a browser tool to build state machines for application logic to make it easier to create and share these types of diagrams. I haven't used it too much yet, but plan to dive into it more in the coming weeks. My early thought is that it's useful to see the big picture of a state machine, but it doesn't scale down to the nitty gritty well.
Listening to Next Week in the Car
I'm going on a fairly long roadtrip next week and have been coming up with a list of media to listen to. Current list:
- Alan Turing: The Enigma (Audiobook)
- Cryptonomicon - Neal Stephenson (Audiobook)
- Tim Ferriss Podcast Episodes (Cal Newport, Tony Fadell, Bill Burr)
I'm interested in your recommendations!
Since I will be traveling for a good bit of the next week, the Dev's Journal may be abbreviated next week, but I'm going to keep the streak alive.